다른 서비스의 데이터가 필요할 때
| topics | |
| types | |
| tags |
#microservice #data-sync #cqrs
|
상황
성과분석 서비스에서 sns에서 성과분석을 하기위한 데이터를 매일 밤11시에 수집하도록 설계했다. 이때 sns서비스의 모든 유저계정,모든 게시물정보가 필요했다.
생각한 방법
1. 분석서비스에서 필요할때 sns-service에 요청하여 데이터를 받는다
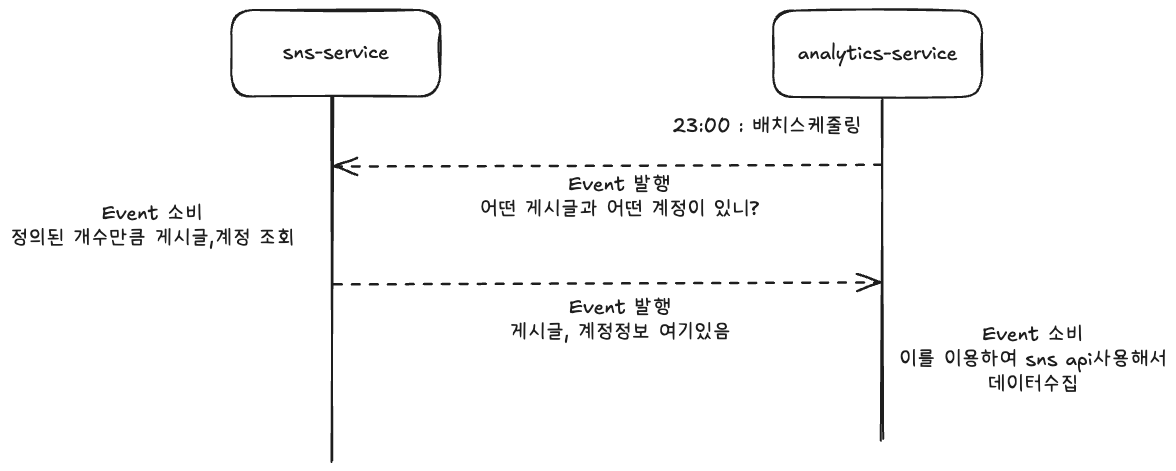
- 장점
- 분석서비스에서 별도의 디비가 필요없음
- 단점
- 모든 유저와 게시물에 대해 받아야함
- But, 한번에 이벤트 발행해서 모든 데이터값을 얻기힘듬
- 이벤트는 최대 1mb만큼만 전송가능
- Therefore, n개단위로 잘라서 받아야함
- 이벤트 발행 개수 : 올림( total / n) * 2
매일 모든 데이터를 다른서비스에서 가져오는 것은 비효율적이고 이서비스에도 부하를 일으킨다고 생각됨
2. 분석서비스에 중복디비를 구성한다
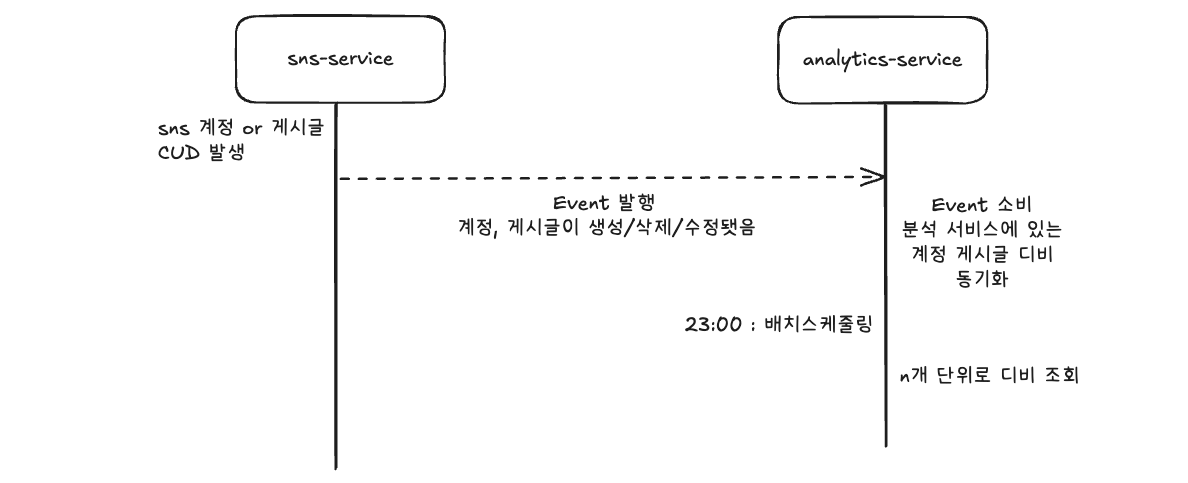
- 장점
- sns-service에 부하가 준다
- 이벤트발행횟수가 압도적으로 준다
- 데이터 얻기까지의 속도가 빠르고 간결하다
- 단점
- sns서비스의 디비와 일관성 있게 유지해야한다
- 일시적인 불일치 발생
- 혹은 이를 보완하기 위한 다른 추가 설정이나 로직을 짜야한다.
- sns서비스의 디비와 일관성 있게 유지해야한다
결론
분석서비스에 중복디비를 구성하는 방식을 정하였다.
- 매 성과분석마다 on demand방식으로 요청받아 처리하는 것이 사용자가 많아질 시 등비수열 형태로 크게 늘어날 것이다.
- 자주 바뀌는 데이터가 아님을 감안하면 중복 디비 만들때와의 부하차이가 매우 크다
- 현재 user와 게시물관련 id 값, 타입등을 받는다. 즉 update도 일어나지 않는다.(create or delete)
- 빠르게 적용되어야할 필요도 없다