빅분기 1유형
| topics | 900-자격증 100-데이터분석 & AI |
| types | 학습 레퍼런스 |
| contexts | 자격증 |
| tags | #빅분기 #파이썬 #판다스 |
빅분기 1유형 - 파이썬 판다스
https://www.kaggle.com/code/user245364/1-100
파이썬, 판다스
# <span id="함수기억안날때"></span>함수기억안날때
print(help(df.dropna))
print(dir(df)) # 이게가지고잇는 속성과 함수를 볼수잇음
# <span id="상관관계피처간의"></span>상관관계(피처간의)
df.corr(numeric_only=True)
# <span id="시리즈를-데이터프레임으로-"></span>시리즈를 데이터프레임으로
.to_frame()
# <span id="멀티인덱스의-시리즈접근"></span>멀티인덱스의 시리즈접근
value = s[('US', 'Pinot Noir')]
# <span id="값-종류-종류수"></span>값 종류, 종류수
.unique() .nunique()
df.drop("시즌", axis=0, inplace=True) # axis는 0이 기본이고 이건 가로를 의미함
df.to_csv('cafe2.csv', index=False) # 인덱스포함하지않겟다
# <span id="인덱스-기준-기본값-ascendingtrue"></span>인덱스 기준 (기본값 ascending=True)
df.sort_index(ascending=False)
# <span id="값기준-정렬-걍-컬럼이름만-잇어도됨"></span>값기준 정렬 걍 컬럼이름만 잇어도됨
df.sort_values(['가격', '메뉴'],ascending=[False, True], inplace=True)
# <span id="인덱스-새로-만들기-droptrue"></span>인덱스 새로 만들기 drop=True
df.reset_index(drop=True)
# <span id="-안에조건이-나오면-그냥이조건이-만족하는-행을구하는것임"></span>[] 안에조건이 나오면 그냥이조건이 만족하는 행을구하는것임
df[df['칼로리'] < 50] # 조건만족하는 행
df['A'] # 컬럼만 선택
# <span id="조건연산자도-가능"></span>조건연산자도 가능
df[cond1 & cond2]
df[cond1 | cond2]
cond = df['메뉴'].isin(['녹차'])
df[cond]
# <span id="값변경"></span>값변경
change = {'룽고':'아메리카노', '그린티':'녹차'} # {이전값:새값}
df.replace(change, inplace=True) # 값이 완전히 일치해여험
df['A'] = df['A'].str.replace('분석', '시각화') # string에서 값교체하는것과같음(부분교체가능)
# <span id="str붙는순간-널문자열로대하겟다"></span>str붙는순간 널문자열로대하겟다
df['A'].str.split()
df['A'].str.contains('기본')
str.lower() str.upper()
# <span id="시리즈값확인"></span>시리즈값확인
menu = pd.Series(['맛난버거 세트', '매운 치킨버거', '더블 치즈버거'])
menu.isin(['맛난버거 세트', '더블 치즈버거'])
# <span id="통계"></span>통계
print("최대값: ",df['가격'].max())
print("최소값: ",df['가격'].min())
print("평균값: ",df['가격'].mean())
print("중앙값: ",df['가격'].median())
print("합계: ",df['가격'].sum())
print("표준편차: ",df['가격'].std())
print("분산: ",df['가격'].var())
print("최빈값: ",df['원산지'].mode()[0]) #최빈값이 여러개일 수도 있으니까!!
print("최빈값의 인덱스: ",df['가격'].idxmax())
# <span id="분위수"></span>분위수
print("분위수 25% 값", df['가격'].quantile(.25))
print("분위수 75% 값", df['가격'].quantile(.75))
cond = df['가격'].quantile(.25) > df['가격']
df[cond]
# <span id="melt-여러개칼람을하나의-칼람으로-합침"></span>melt 여러개칼람을하나의 칼람으로 합침
# <span id="id_vars-유지될-칼럼-value_vars-합처질-칼럼"></span>id_vars : 유지될 칼럼, value_vars 합처질 칼럼
# <span id="기본값은-각각-variable-value입니다"></span>기본값은 각각 'variable', 'value'입니다.
# <span id="원래-컬럼이-name-math-eng-kor가-잇으면"></span>원래 컬럼이 name, math, eng, kor가 잇으면
pd.melt(df, id_vars=['Name'])
# <span id="이러면-variable의-값으로mathengkor가-생김"></span>이러면 variable의 값으로(math,eng,kor)가 생김
# <span id="그루핑-sql생각하면될듯"></span>그루핑 (sql생각하면될듯)
# <span id="원두와-할인율-기준-평균"></span>원두와 할인율 기준, 평균
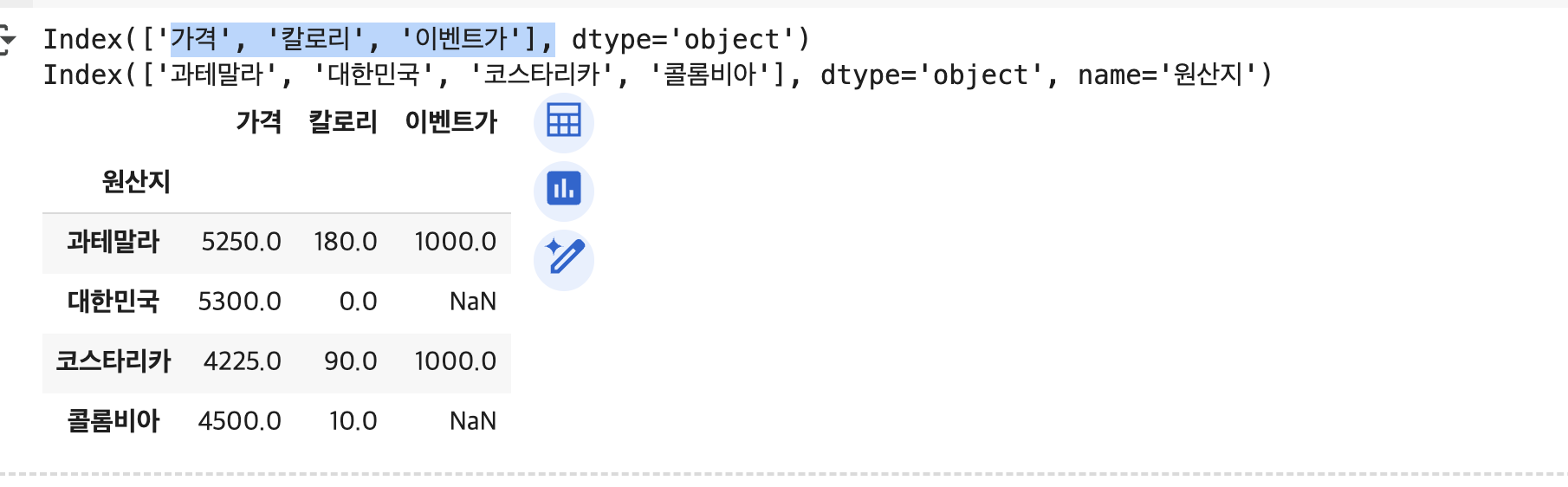
df.groupby(['원산지']).mean(numeric_only=True) # 사진확인
ndf = df.groupby(['원산지', '메뉴']).agg(['mean', 'sum']) # 이렇게 되면 멀티인덱스됨
# <span id="groupby-agg안에꺼가-다-인덱스됨"></span>groupby , agg안에꺼가 다 인덱스됨
# <span id="agg여러집계함수동시적용"></span>agg여러집계함수동시적용
# <span id="시계열데이터"></span>시계열데이터
df['DateTime2'] = pd.to_datetime(df['DateTime2'], format='%Y-%m-%d %H-%M-%S')
df['year'] = df['DateTime1'].dt.year # month, day, hour, minute, second
df['DateTime1'].dt.dayofweek # 요일 0: 월요일'
df['DateTime1'].dt.to_period('Y')
# <span id="y-연도-q-분기yyyyqn-m-yyyy-mm-d-yyyy-mm-dd-h-2024-06-16-1300"></span>Y : 연도, Q : 분기(yyyyQn) , M : yyyy-mm , D : yyyy-mm-dd ,H: 2024-06-16 13:00
# <span id="시간차이로-계싼가능-뒤에다-s붙여야함"></span>시간차이로 계싼가능 뒤에다 s붙여야함
day = pd.Timedelta(days=99)
df['100day'] = df['DateTime4'] + day
# <span id="병합"></span>병합
full_menu = pd.concat([appetizer, main], axis=1) # 수평
full_menu = pd.concat([appetizer, main], ignore_index=True) # 기본 0(수직으로 병합)
# <span id="두-데이터프레임을-menu를-기준으로-병합-innerjoin"></span>두 데이터프레임을 'Menu'를 기준으로 병합 (innerjoin)
menu_info = pd.merge(price, cal, on='Menu')
# <span id="count-size-행개수새는거"></span>count, size (행개수새는거)
# <span id="count-결측치-제외-size-결측치포함"></span>count < 결측치 제외 , size < 결측치포함
# <span id="groupby"></span>groupby
reviews.groupby(['price']).max(numeric_only=True)
reviews.groupby('price')['points'].max().sort_index()
# <span id="애는-point기준으로-집계"></span>애는 point기준으로 집계
# <span id="apply"></span>apply
def func(row):
# row는 Series, 행 전체 정보 사용 가능
return row['A'] + row['B']
df['new_col'] = df.apply(func, axis=1)
# <span id="map"></span>map
import pandas as pd
df = pd.DataFrame({'col': ['A', 'B', 'C', 'A']})
mapping = {'A': 2, 'B': 0, 'C': 1}
df['col_encoded'] = df['col'].map(mapping)
print(df)
group