DA_4데이터 모델링
| source | |
| topics | |
| index | 자격증 |
| tags |
##DA ##데이터모델링 ##ERD ##정규화 ##물리모델링
|
데이터 모델링 이해
데이터 모델 : 현실세계 우리가 관심있어하는 대상을 db화하기위한 개념적 도구
구성요소와 표기법(개체 관계모델)
e-r다이어그램 보통이용
프로세스 중심보단 데이터 중심 설계를 주로 사용
하나의 엔티티가 반드시 물리적으로 하나의 테이블이 되지않음
엔티티
- 집합 ex 학생
- 앤티티의 인스턴스(개체) ex 홍길동
- 가로한줄
- 앤티티의 인스턴스(개체) ex 홍길동
- 표기법
- er: 네모
- 바커: 둥근 네모에 왼쪽위에 명(안에잇음)
- I/E: 네모 왼쪽 위에 명(밖에잇음)
- 엔티티(실체) , 엔티티타입(실체형) 근데 둘다 비슷한말임
속성
- 집합의 특성 ex : 학번
- 표기법
- er : 타원형
- 바커 : * (반드시 저장해야함) o(옵셔널함)
- I/E: 걍 적는데 식별자는 맨위에 분리되어있음
- 속성의 값의 범위 == 도메인
- 식별자 : 키인데 논리적관점
- 본질 식별자를 여기서 식별자로 함
- 후보,대체,인조,실질식별자가 있음
- 표기법
- er : 밑줄침
- 바커 : #
- 본질 식별자를 여기서 식별자로 함
- 다중치속성: 값이 여러개
- 표기법 : 2줄그음
- 새 엔티티만들어서 1:M으로 (공모주햇을때 생각)
- 유도 속성 : 다른속성들에 의해 유도되는값
- 표기법 : 점선
- 실제구현 ㄴㄴ
관계
- 관계에 참여하는 개체 수로 이항관계 4항관계
- 표현
- er : 선
- 바커
- conditional : 실세계서 발생하는 동사적 언어를 표시
- 필수조건 : 실선
- 선택조건 :점선
- I/E
- 선택, 필수 : 점선 실선
- 해쉬마크(|) 와 까막이발로 관계구분
- 까막이발 : n
- 해쉬마크 : |
- 해쉬마크만 있으면 정확히 하나만허용
- 원 : 0허용여부
- 선택조건(점선)은 무저건 원모양 있음
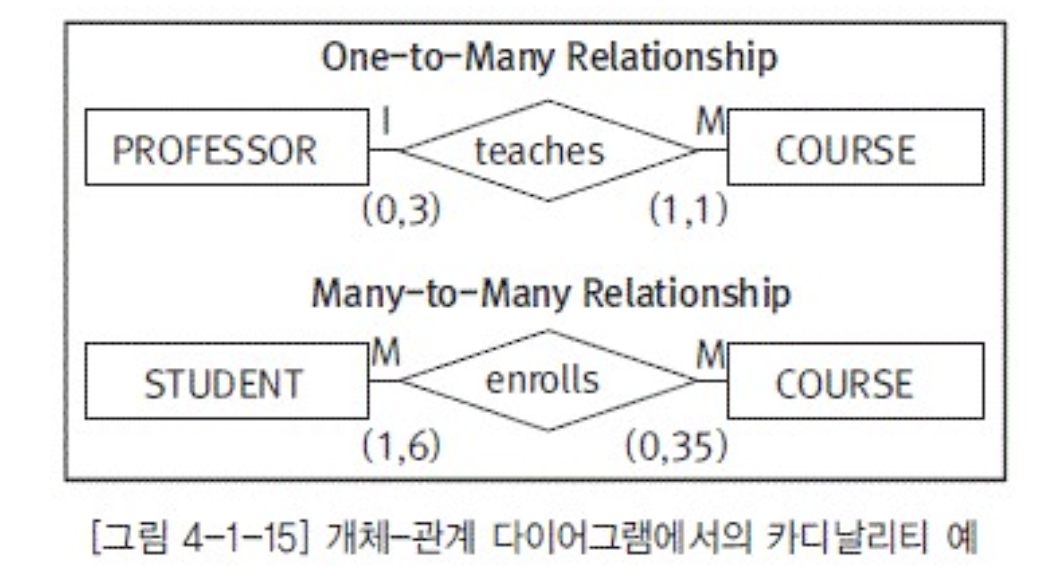
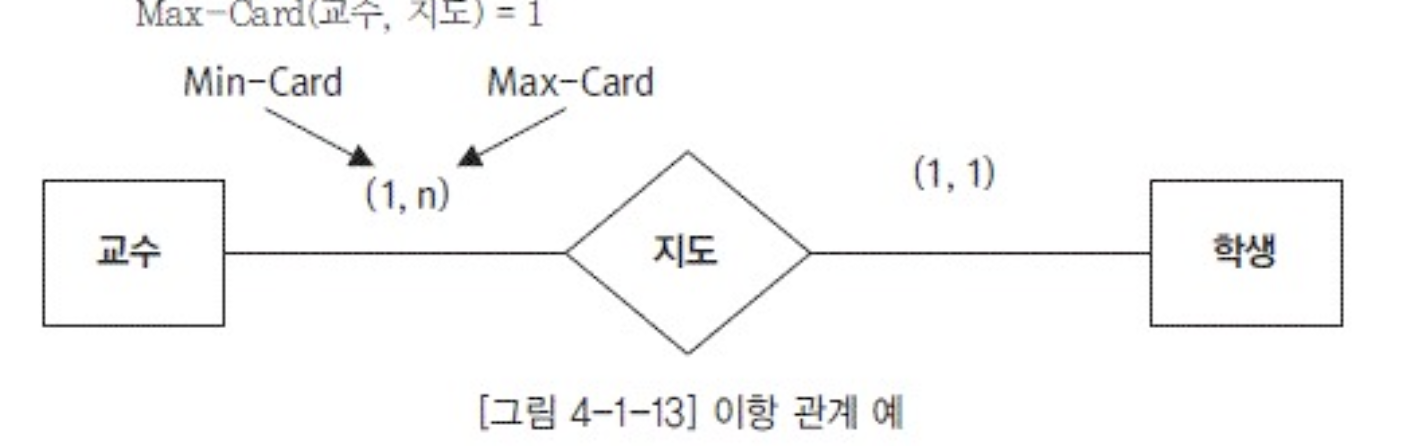
- 카디널리티: 연결제약조건(min,nax)
- 매핑카디널리티 : 1:1 , 1:n, n:n
- 관계맺는 두개체에서 각 인스턴스가 연관성을 맺을 수 있는 상대인스턴스 개수
- 카디널리티 매핑카디널리티 크로스로 생각
존재 종석: 한엔티티가 다른 엔티티들 존재에 영향받는경우
타입
- 슈퍼타입 : 개체에서 전체집합 (학생)
- 서브타입 : 부분집합 (초딩중딩고딩)
- 구분자가 있기도함
- 객체지향적인듯
- 표기법
- 바커 : 서브타입을 상자로 나타냄
- I/E : 베타적 서브타입(반원에 엑스), 포괄적 서브타입 (반원)
- 베타적 : 슈퍼타입은 최대 하나의서브타입과 관련이 있을수 있다
- 포괄적 : 여러개
- 예를들면 타입을정할때 머 여러개의타입이될수잇고 하나의타입이될수 있잔슴? 그거생각하면될듯
개념데이터 모델링
e-r모델 , 사용자와 상호작용
핵심엔티티들과 관계를 정의
주제영역 정의
기업이 사용하는 데이터의 최상위 집합을 의미
- 응집도 있게(안에있는건 관계밀집ㅇㅇ 밖엥)
- 데이터는 관계구조로 표현됨
- 하양식 분석이 용이하지 않음
- 계획수립단계는 하양식 분석을 원칙으로 함, 검증을 위해서 부분적으로 상향식
- 주제영역은 계층적으로 표현할 수 있어서 하양식으로 분석가능
- 현행시스템을 개선하려고할경우 상향식 분석을통해 주제영역을 설정하고 관리함
- 분류 기준
- 데이터 관점의 분류
- 데이터를 쓰는 주체나 데이터로하는 짓거ㄹ를 근거해서 분류
- 데이터 관점의 분류
- 원칙
- 업무 요건 추가에 대한 유연성 보장
- 확장성, 융통성이 있어야함
- 주제 영역간 균형유지
- 전체적인 균형을 유지해야함
- 너무 상세하거나 방식이 다르면안좋다
- 업무 요건 추가에 대한 유연성 보장
- 이름 규칙
- 실 업무에서 보편적으로 사용하는업무 용어를 부여
- 유일한 단수형 명사 사용
- 데이터의 그룹을 의미하는 이름을 부여 - 활동을 의미하는 이름 배제
원칙
- 데이터 중복 최소화
- 데이터 확장성 보장
- 데이터 관령성 및 편의성 확보 : 참조모델도 참고하는ㄴ것도 조음
절차
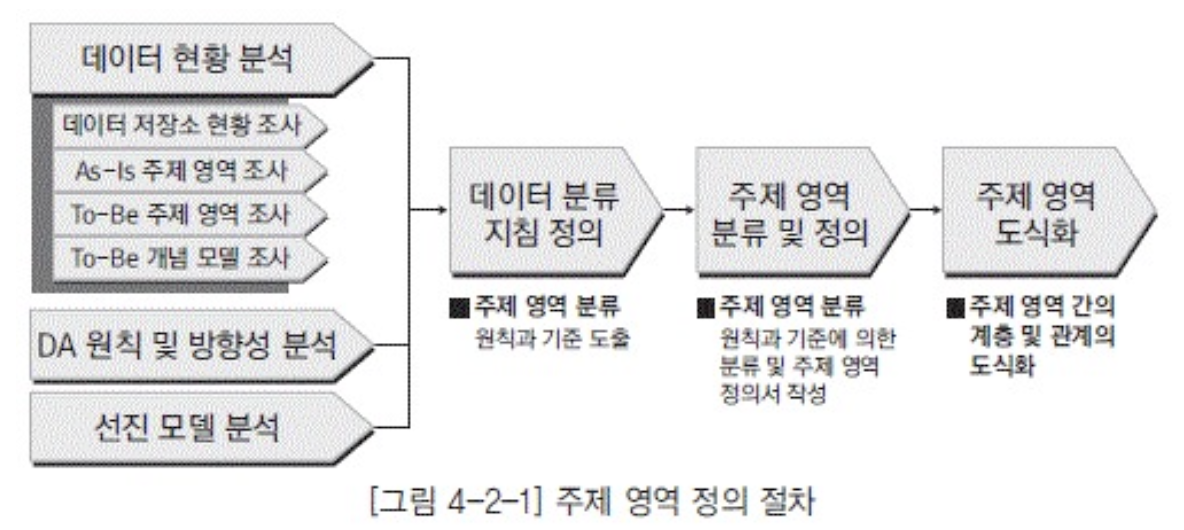
분류 방법
- 1차분류 : 주요 데이터 집합의 유형정리
- 데이터 성격,특성 고려
- 업무 변화에 민감하지 않도록 정의
- ex) 주체, 상호작용을 발생하는 대상으로 분류 , 상위개념으로 분류
- 2차분류 : biz 활동에 필요한 데이터 분류
- biz는 비지니스임
- biz활동에 필요한 분석 주제와 현황등의 영역으로뷴류
- 기본,상세,관계 같은기능적 구성관점에서 접근
- ex) 관계자 기본, 관계자 상세, 관계자 관계
- 3차분류 : 2차 영역의 세부 주제 영역 분류
- biz활동에 필요한 분석 주제와 현황 등의 영역으로 분류
- 사용자에게 제공되는 실제 데이터로서의 관점(=업무적 관점)으로 분류
- ex) 관계자 : 고객,법인,조직 등
활용
- 데이터의 계층적 구조를 파악하는데 도움됨
- 업무기능과 병행하여분석하는 경우, 분석으 최상위 단위역할을 하여 품질 확보에 기여
- 주제 영역 계층과 업무 기능계층간의 대응관계를 확인
- 효율적 데이터 관리를 위한 기준 제시, 구성의 청사진 제공
- 장점
- 데이터 및 업무활동 모델의 품질 보증
- 플젝 관리 용이
- 모델개발 조정 용이
- 레포 관리 용이
- 상세사항의 전개 혹은 축약 가능
도출
- 업무에서 사용하는 데이터의 명사형 도출
- 업무기능의 이름으로부터 도출
- 탑다운,바텀업 접근방법
- 분석단계에서 도출
- 아키텍처모델정련하는 과정
- 데이터모델을 상세화하는 과정
정의 내용
- 레벨 : 주제영역의 계층수준(1차,2차,단위..등)
- 주제영역명
- 설명
- 대표 엔티티
후보엔티티선정
후보의 자격여부만 가려내는선에서수사를 멈춰야함
다양한 경로로 수집해야함
수집
- 기좀 시스템 도큐먼트
- 현업 장표 보고서
- 현업 인터뷰
- 관련 전문 서적
- 데이터 흐름도
- 타 시스템 자료
- 현장 조사
엔티티 후보 식별
- 엔티티 후보의 개념 정립
- 단어가 의미하는 진정한 집합이 무엇인지 정의해야함
- 관리 대상 판별
- 앞으로 관리해야하는냐도 생각해야함
- 집합여부 확인
- 관리하고자하는 개체(세로)와 속성(가로)이있는가
- 세로 * 가로 = 면접 = 집합의 크기
유의사항
- 엔티티 가능성이있다고 생각하면 검토대상에올리셈
- 너무 깊게 ㄴㄴ
- 동의어처럼보여도 함부로 버리지마셈
- 개념이모호한 대상은 일차로 그개념을 상식화해서 이해
- 예외의 경우에 너무 집착 ㄴㄴ
- 단어하나하나에 집중해서 판단
엔티티 후보 분류
- 우선 적용 대상 분류
- 키 엔티티
- 행위를발생하는 주체나 목적어(명사임)
- 부모가 없음
- 다른 엔티티 도움없더라도 그 개체를 새롭게정의가능
- 규칙과 부모으차이는 확실하다
- ex) 사원은부서가 없이 태어날수 있다.
- 부서가 결정되지 않음녀 탄생시키지않겟다는 규칙은생성가능하다
- ex) 사원은부서가 없이 태어날수 있다.
- 메인엔티티
- 키엔티티가 행위를 함으로써 발생하는 행위의 집합중에 더다른 하위행위를 발생시키는 주체나 목적어가 될수 있는 엔티티
- 즉 부모엔티티가 있어야 테어날 수 있는 엔티티
- 크기에 따라 계층 깊이가 다른데 위쪽에있는 즉 중심에있는거 걸 메인엔티티라고하고 나머진 엑션으로 정의
- 엑션엔티티
- 나머지 엔티티
- ex) 수납기관은 엔티티가 아님(두집합을 연결한 모습임으로 관계임)
- 행위의 본질과 개체의 본질이 같이 혼합되어 있으면 안됨
- 각각은 ㄱㅊ
- 키 엔티티
- 선정한 엔티티를 데이터 영역별로 분류
- 탑다운,바텀업방식이 있을 수 있음

핵심엔티티 정의
의미상 주어 정의
- 같은말 : 진주어, 본질 식별자
- 카드버놓는 임의로 만든거임(인조식별자)
- 카드 받은사람 이런건 실제로 있는 것. 본질적인 식별자(=진주어)임
- 정의 의의
- 집합의 의미를 명확히함
- 정의 예
- 진주어로 상속관계를 규명해 올라갔을 때 제일 위에 있는게 키엔티티
- 키엔티티는 무조건 ?:1 관계임
- 역은 성립하지않음
- 키엔티티는 무조건 ?:1 관계임
- 진주어로 상속관계를 규명해 올라갔을 때 제일 위에 있는게 키엔티티
코드성 키엔티티 모델링
- 기준
- 자식엔티티 가짐?
- 단순 불류용이면 지금 도출 ㄴㄴ
- 자신만의 다양한 속성을 가짐?
- 다양한 속성이 있으면 join연산이 분명 발생할것이므로 도출해주는것이 좋다.
- 여러 엔티티에 관계를 가짐?다양한 종류의 관계를 가짐?
- 자식엔티티 가짐?
집합 순수성
- 엔티티는 반드시 순수한 본질 집합이 되어야함
- 개체 or 행위 둘중 하나의 집합이 되어야함 , 결합 ㄴㄴ
- ex ) 납입자는 고객과 납입이 결합됨
- 예외사항
- 관계가 엔티티로 변화는 경우
- M:M이면 더이상 관계로만 존재가 불가능함
- 이를 릴레이션 엔티티 or 제휴 엔티티라고 함
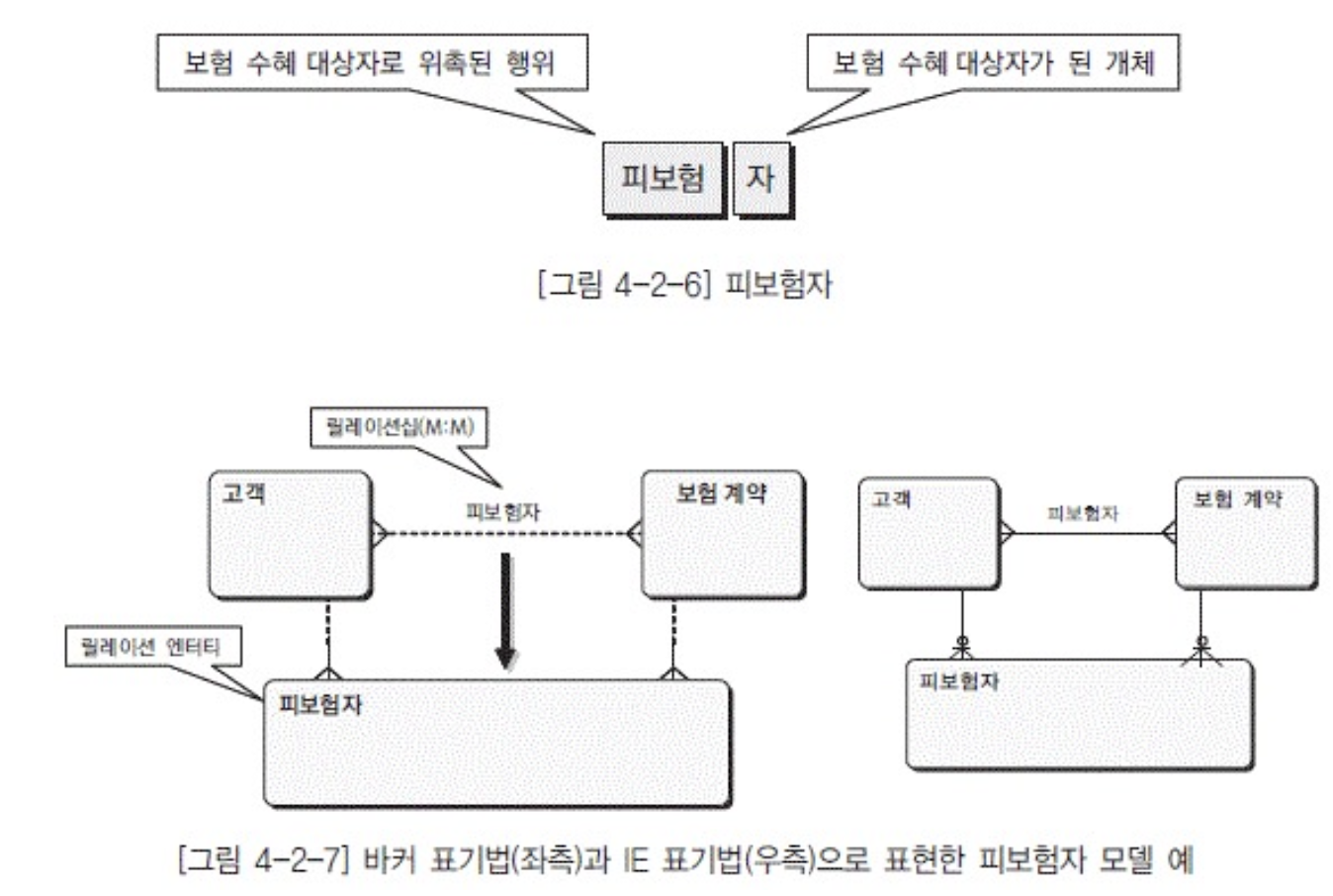
- 일부 집합 정의
- 합성으로 보이는것중에 이후 개체를 특정하기 위해 넣은 말일 수 있음
- ex ) 금융 기관
- 배타적 관계대체
- 엔티티가 여러엔티티랑 동일한 관계를 맺는경우
- ex) 배송처 : 복합관계 vut 계속 늘어날 가능성이높다면 빈번한 수정이 발생하기 에 약간의 집합적중복이 발생하더라도 별도의 엔티티를 생성랗ㄹ 필요가있음
- 관계가 엔티티로 변화는 경우
집합 동질성
- 집합에 들어갈 개체들의 동일한 성질을 어디까지 한정할것인가
- 집합의 범위 체크
- 사원을 사내 사원일숭ㄷ도잇고 프리랜서도 있을 수 있고 등..
엔티티 명칭
- 적절한 엔티티 명칭
- 오해최소화시킬 수 이썽야함
- 각속성은 엔티티와 직접적으로 관련있어야
- ex) 교육일정에 교육장소같은게 있으면안됨 , 이르면걍 개설 강좌 이렇게 봐야함
서브타입
- 고려사항
- 교집합 허용 불가
- 서브타입의 합이 전체집합
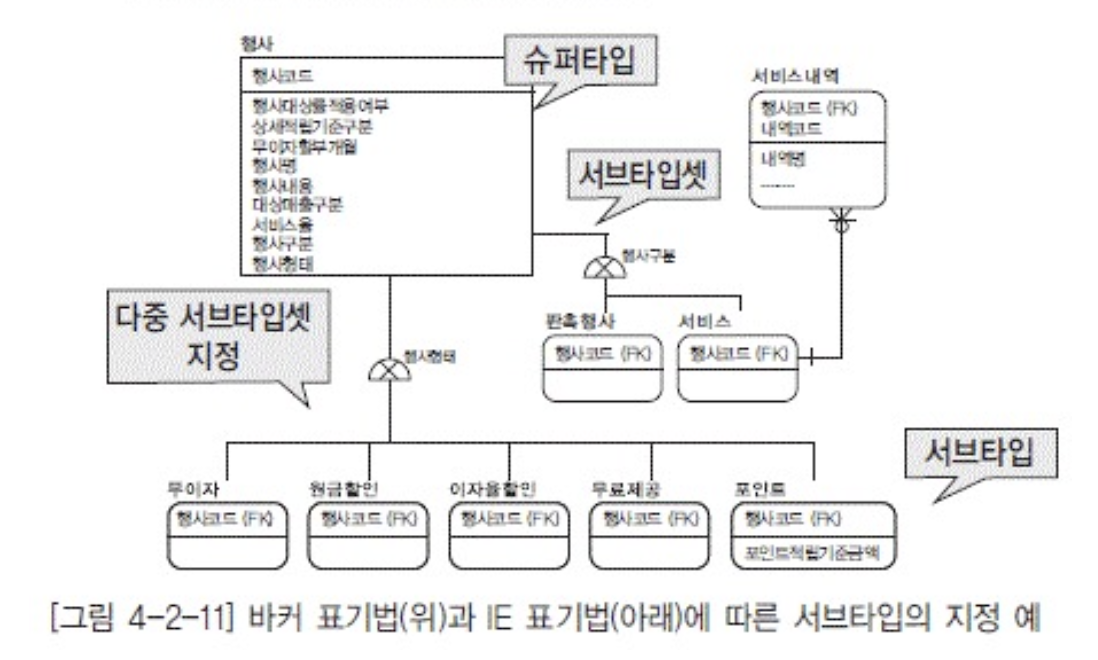
- 표현 기준
- 개별 속성을 가지는 경우
- 개별 관계를 가지는 경우
- 가독성을 증진시키고자 하는 경우
- 도출 기준
- 분류 속성에 따라 엔티티 정보가 차별화 되는 경우
- 다수의 선택적 속성이 존재하는 경우
- 선택적 관계가 존재하는 경우
- 분할함으로써 관계가 필수적으로 변하는지
- 도출 절차
- 분류 속성값 확인
- 분류 속성값에 의해 분류되는 서브타입 파악
- 필수적 ,선택적 분할을 정의
- 서브타입별 속성할당
- 슈퍼 타입의 관계를 서브타입에 정의
- 활용
- 속성,관계 의 선택성 제거 : 가독성 향상
- 명확성과 복잡성의 트레이드오프 관계
엔티티 통합과 분할
통합 > 단순화,유연성증가, 모호한희석 / 분할 > 명확성 up , 유연성down복잡도 up
- 엔티티 독립성
- 어떤 엔티티에도 포함되지 않는 독립적인 집합인가
- 엔티티 분할/통합
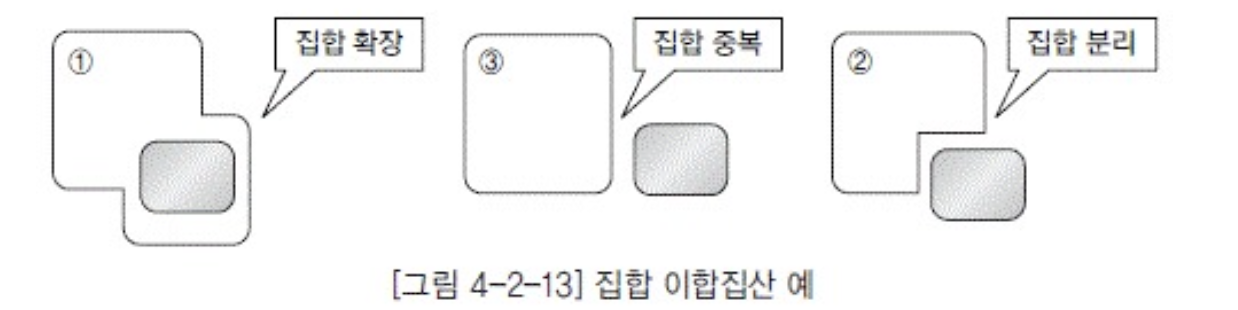
- 집합 분리: 겹치는부분을 한집합에서만 갖게해 둘사이를 완전히 분리
- 집합 확장: 겹치는부분을 포함하게함
- 집합 중복: 교차되는 부분이 있더라도 두집합을 별개의 집함으로 간주
- 동질성확대를 위하거나(유사성이강한경우), 유연성을 향상하기 위해 통합하기도함
엔티티 정의 기술, 정의서 작성
- 정의 기술
- 전달되어야할것
- 집합의 구성상특징
- 데이터 집합의 개념 및 성격
- 데이터 crud시 특이사항 및 오너십 등 기타특이사항
- 전달되어야할것
- 정의서
- 추가적인 상세정보 항목을 문서화,의사소통 수단으로 사용
- 저으이 식별자 처리형태 특기사항 분석사항 등이 담김
관계 정의
관계 : 엔티티 들사이의 관계 를 말함 , 관리하고자하는 직접적인 관계(직접 종속)를 의미
- 관계도 일종의 집합임
- 두 엔티티 간에 하나이상의 관계가 존재할 수 있다
- 서로다른 업무규칙을 가진경우
- 관계는 FK로 구현되어 참조 무결성(RI)으로 데이터 정합성 유지의 역할을 하게 됨
- 관계의 관점
- 항상 두 엔티티 간에 존재
- 항상 두개의 관점을 가지고 있음
- 데이터의 양방향 업무 규칙을 표현
- 관계를 통하여 정보로서의 활용 가치 상승
관계 표현
- 관계 형태
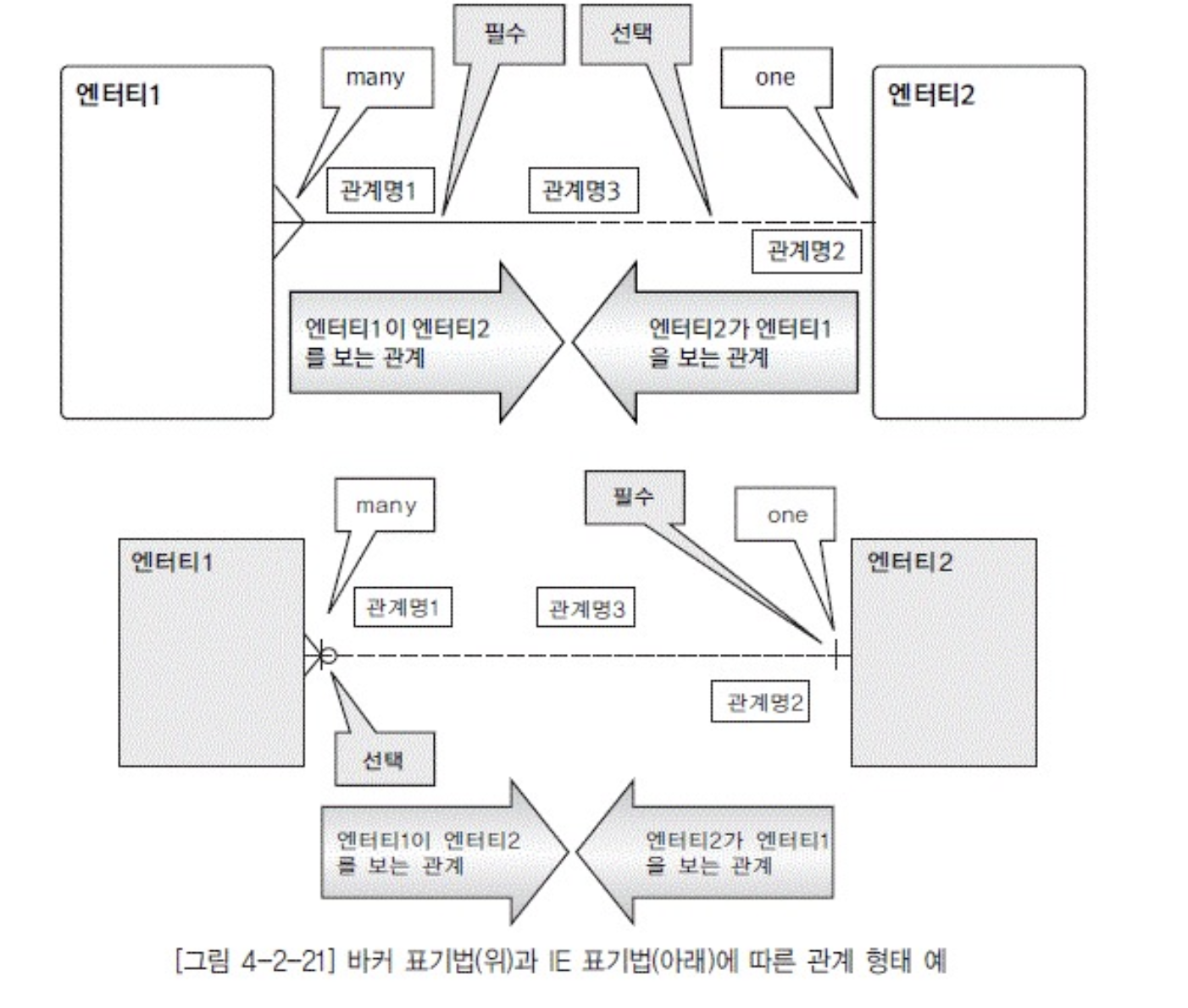
- 하나이상(M), 단하나(1), 선택사항(ㅇ 옵셔널)
- 형태
- 일반적인 형태
- 주로 참조하는 엔티티(M,자식)는 참조되는 엔티티(1,부모)가 반드시 존재해야하는 경우가 많이 나타남
- 반대로 1쪽은 반드시 M쪽과 관계를 맺지 않아도 되는 것이 일반적
- 바람직한 형태
- 가능한 직선 관계를 가지도록(선택말고 필수)
- 특히 M쪽에서
- 가능한 직선 관계를 가지도록(선택말고 필수)
- 일반적인 형태
- 관계명

- 각자 상대방 입장에서 관계명 기술
- 현업에서 사용하는 간결한 동사형으로 표현
- 현재시제를 사용
- 업무적 연관성을 나타내는 이름 부여
- 유일성확보는 못됨
- 애매모호한 용어 배제
관계 정의 방법
한쪽 엔티티 기준으로 상대 엔티티와의 관계를 규정하고 다음에 반대로
- 관계 구문 이해
- 관계 정의 절차
관계형태
- 1:1
- 필수 -선택
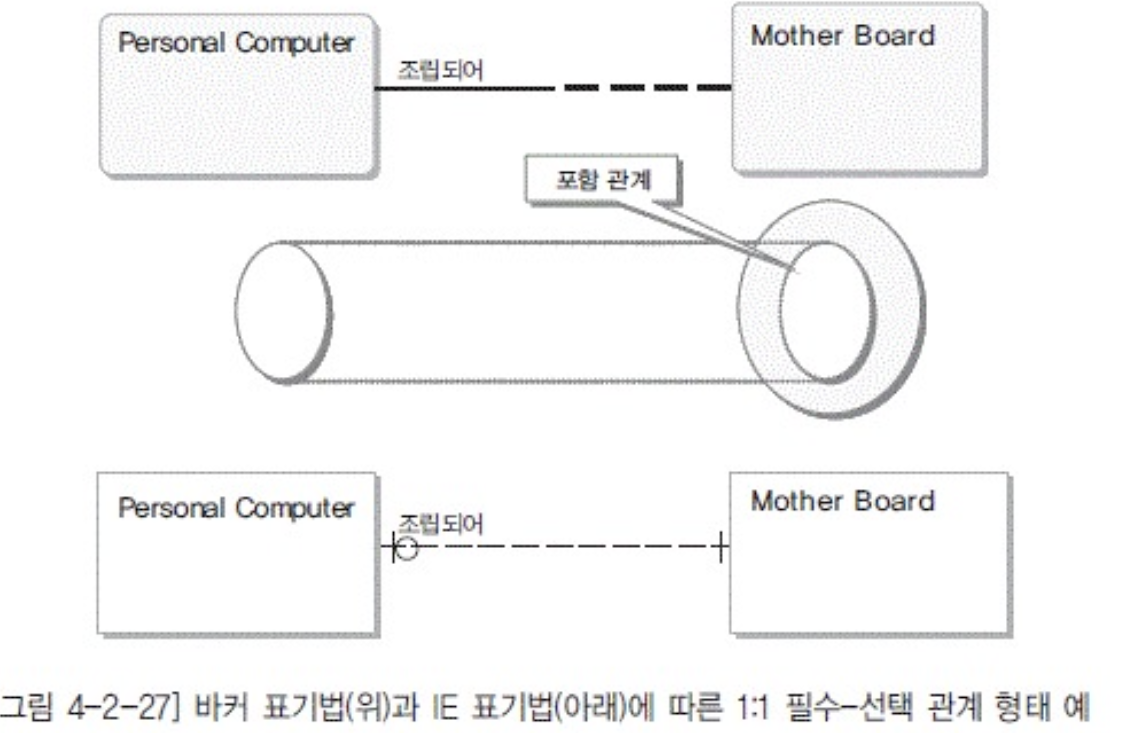
- 좌측의 Personal Computer가 조립되기 위해서는 반드시 단 하나씩의 Mother Board를 가져야 한다. 그러나 Mother Board는 아직 조립에 사용되지 않은 것이 존재할 수 있으므로 위와 같은 관계가 나타난다.
- 보면 바커조립법이랑 IE표기법이랑반대임
- 바커 가까운게 개체에 가까운게 입장 IE는 반대임
- 필수-필수
- 동치, 보통 수직분할 (논리적관점에서 하나의 데이터집합)
- 선택-선택
- 필수 -선택
- M:1
- 계층구조로 이해해도조음
- M : 자식, 1: 부모
- 자식은 부모를 반드시 참조하게 하는 편이 조은모양
- 필수-필수 : 일반적이진않음
- 필수 - 선택(부모 옵셔널) : 가장일반적임
- 필수 - 선택 (자식 옵셔널) : 드뭅
- 선택- 선택 : 흔함. 근데 선택성이 증가할수록 모호성도 증가함
- M : M
- 관계가 덜풀려진형태
- 해소하려면 새로운 엨ㄴ티티가 필요하다
- 양쪽다 1:M 관계가 나타날때
- 분해할때 항상 1:M으로 분해되는건 아님 새로운 M:M이나올 수 있음
- 관계가 덜풀려진형태
다중 관계처리
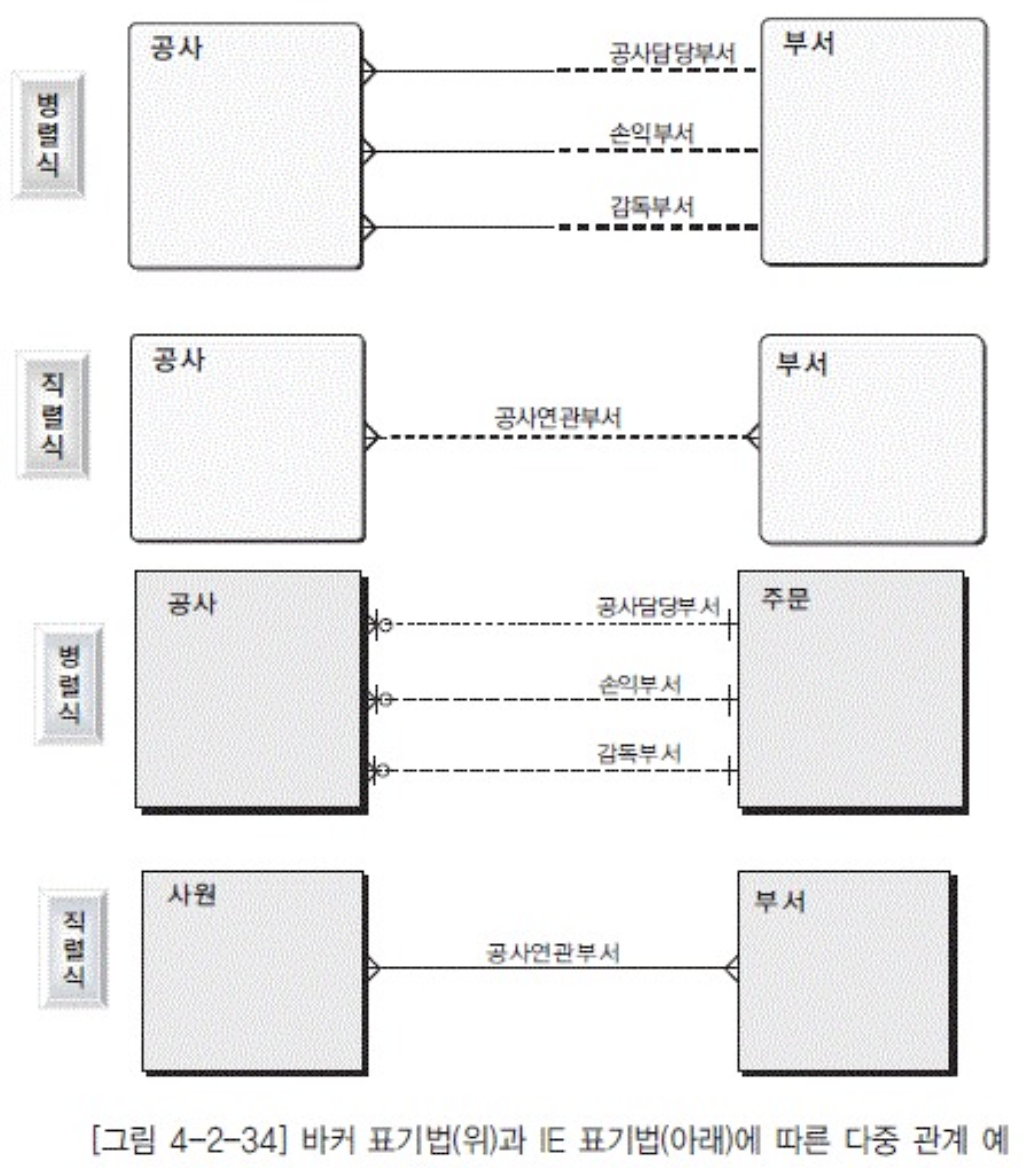
하나 이상의 관계를 가지고 있는 상태를 말함 (M:M )
- 병렬식 관계
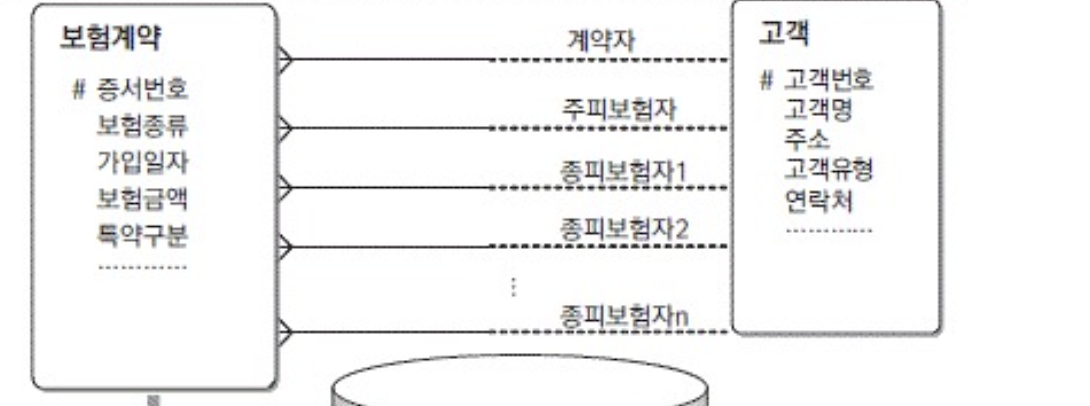
- 두엔티티 사이에 존재하는 관계를 별도의 관계로 간주
- 특징
- 테이블이 될때 여러개의 속성(칼럼)으로 나열된다
- 새로운 테이블 추가 할 필요없음
- 인덱스 수 증가하고 sql이 복잡해진다
- 새로운 관계의 추가 , 관계형태의 변경등에 매우취약하다
- 관계 내용별로 상세정보를 관리할 수 없다
- 직렬식 관계:
- 여러관계를 모아 상위로 통합해서 관리했을때
- 처리 전용엔티티를 생성하고 서브타입으로 관리함
- 특징
- 새로운 엔티티 추가되어야함
- row 형태로 나타낸다. > 유연성 높음
- 인덱스 수 감소하고 sql이 단순해짐
- 관계 내용 별로 상세정보 관리가능
특수 관계
- 순환관계
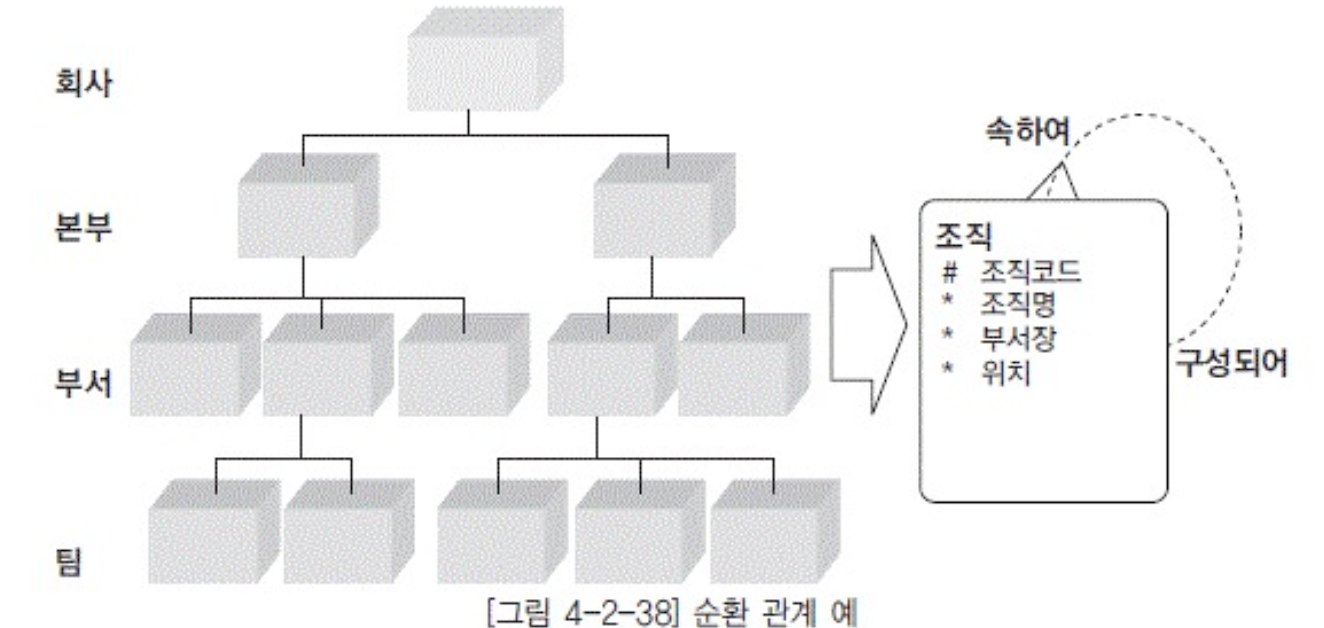
- 자기자신과 맺는관계
- 필수 관계이면안됨(무한루프)
- BOM
- 네트워크 구조
- M:M순환구조
- 두개의 1:M 관꼐 모델로 구체화 됨
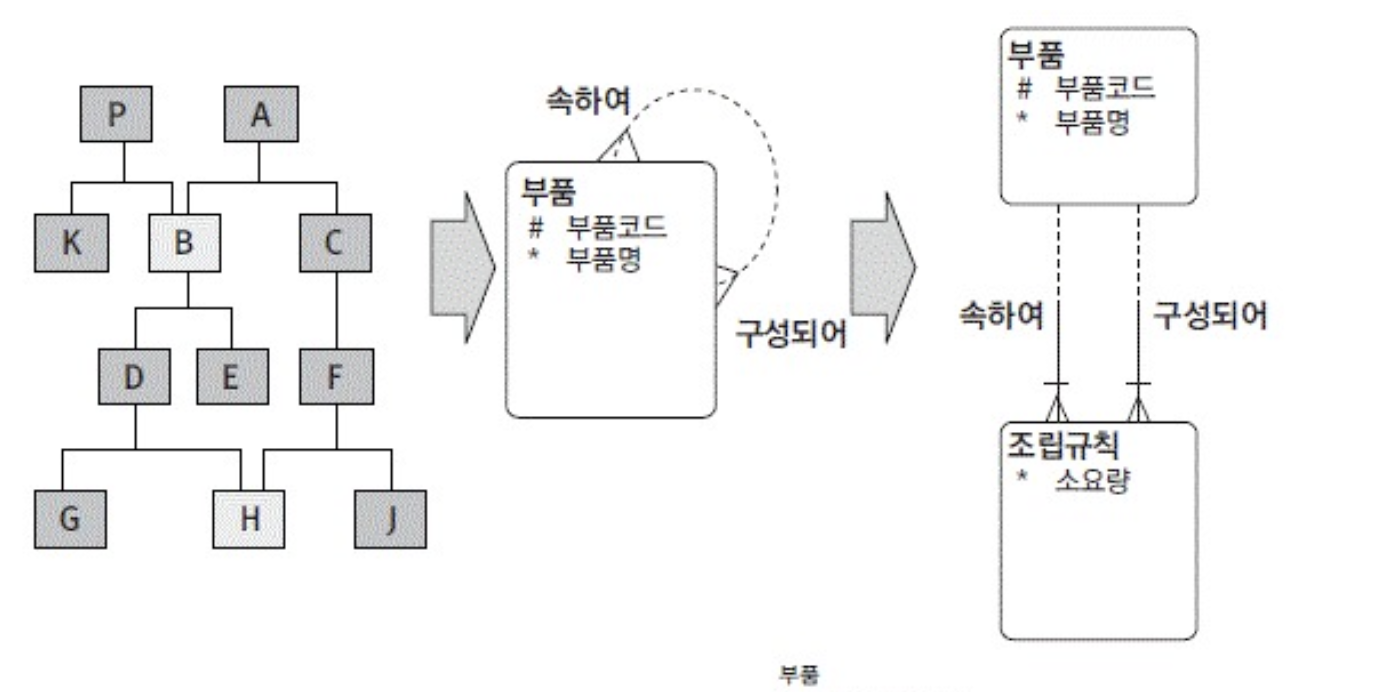
- Arc or 배타적 관계
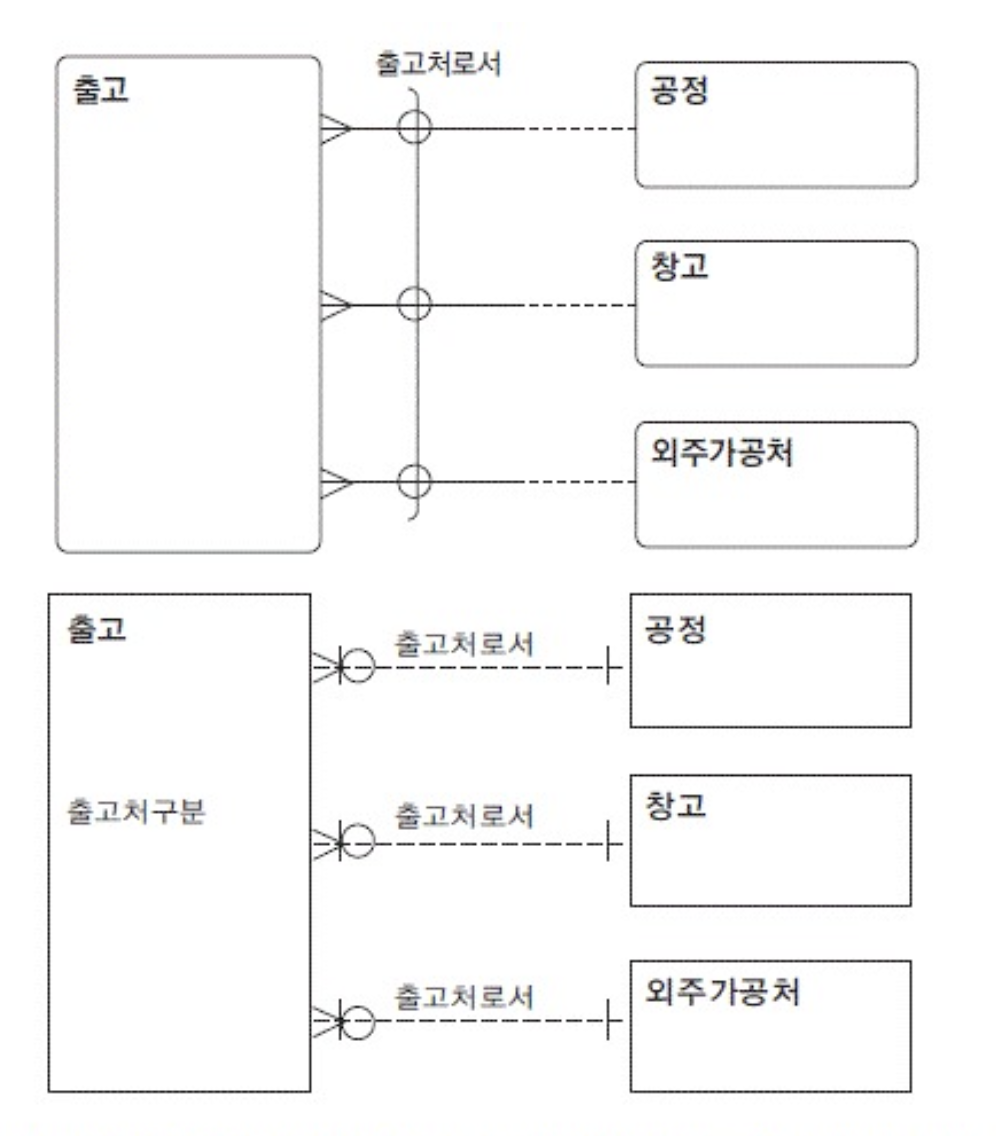
- 두개이상의 다른 엔티티의 합집합과 관계를 맺는걸
- 저기서 아크가 출고인듯
- 출고는 저 공정 창고 외주가 공처 3중하나만 관계를 맺을 수 있음
- 어떤 엔티티는 다수의 아크를 가질 수 있음(지정된관계에는 하나의 아크만 사용)
논리데이터 모델링
데이터에 누거 어케 엑세스하는지 등을 정의
가장핵심임
ERD그림
절차보단 데이터에 초점을 두고 모델링
속성정의
- 엔티티에서 관리되는 정보
- 분리될 수 없는 최소의 데이터보관 단위
- 속성도 일종의 집합으로 볼 수 있음
- 릴레이션도 일종의 속성이 된다
- 속성은 서로 독립적이여야함
기본 구성요소
- 속성명
- 업무서 일반적으로 사용하는 용어, or 함축어 or 약어
- 셀체명은 속성명으로 사용하지 말아야
- 도메인
- 속성이 지닐 수 있는 값에 대한 ㅈ제약조건
- 데이터타입이나 길이 ,허용값, 디폴드값
- 선택성
- nullable 여부
속성 후보 도출
- 수집
- 구문서자료
- 현업장표보고서
- 사용자와 협의
- DFD,DD(데이터사전)
- 전문 서적 및 자료
- 다른 시스템 자료
- 후보 선정 원칙
- 원시 속성으로 보이는 후보는 버리지 않는다
- 소그룹별로 후보군을 만들고 가장근접한 엔티티에 할당
속성 검증 및 확정 시 확인사항
- 최소단위까지 분할
- 최소단위까지 분할한 후 관리필요에 따라 통합
- 예시: 매출일자 보통 yy mm dd 각각 나눌쑨잇겟지만 일자라는 의미를 가지니깐 통합해야함
- 하나의 값만 가지는지 검증
- 여러값을 가지거나 반복되는 속성은 잘못된 속성임
- 반복되는건 1차정규화의 대상
- 추출속성인지 검증
- 다른속성에의해 가공되어서 만들어질 수 있는 값인지 검증
- 보다 상세하게 관리할 것이냐
속성 정의시 유의사항
- 의미가 명확한 속성명칭을 부여한다
- 유일한 복합명사 사용
- 순번보단 계약 순번, id보단 고객id같이 복합해서 써라
- 기간 - 연단위인지 달단위인지 알수가엄슴
- 단수형으로 속성명정하셈
- 표준단어 제정
- 이걸미리하면 데이터모델만들때 그기준을 준수하거나 하기 편함
- 작의전인 전용 금지
- 전용 : 예정된 곳에 쓰지않고 다른데 돌려쓰는것
- 속성의 의미를 추상적이고 모호할게 정의해서 개발자들이 각기다르게 이해할때 나타남
엔티티 상세화
식별자 확정
- 식별자 종류
- 본질 식별자(primary uid or intrinsic uid)
- 주(실질) 식별자(actual uid)
- 대체 식별자 (secondary uid)
- 개념 데이터 모델링에서 핵심엔티티,키엔티티 등을 정의 된걸 활용
- 키엔티티는 식별자를 창줘해야하고
- 행위는 방법에 따라 하양식,상향식으로 접근해야함
- 부모는 반드시 확인해야함
- 본질 식별자 확인
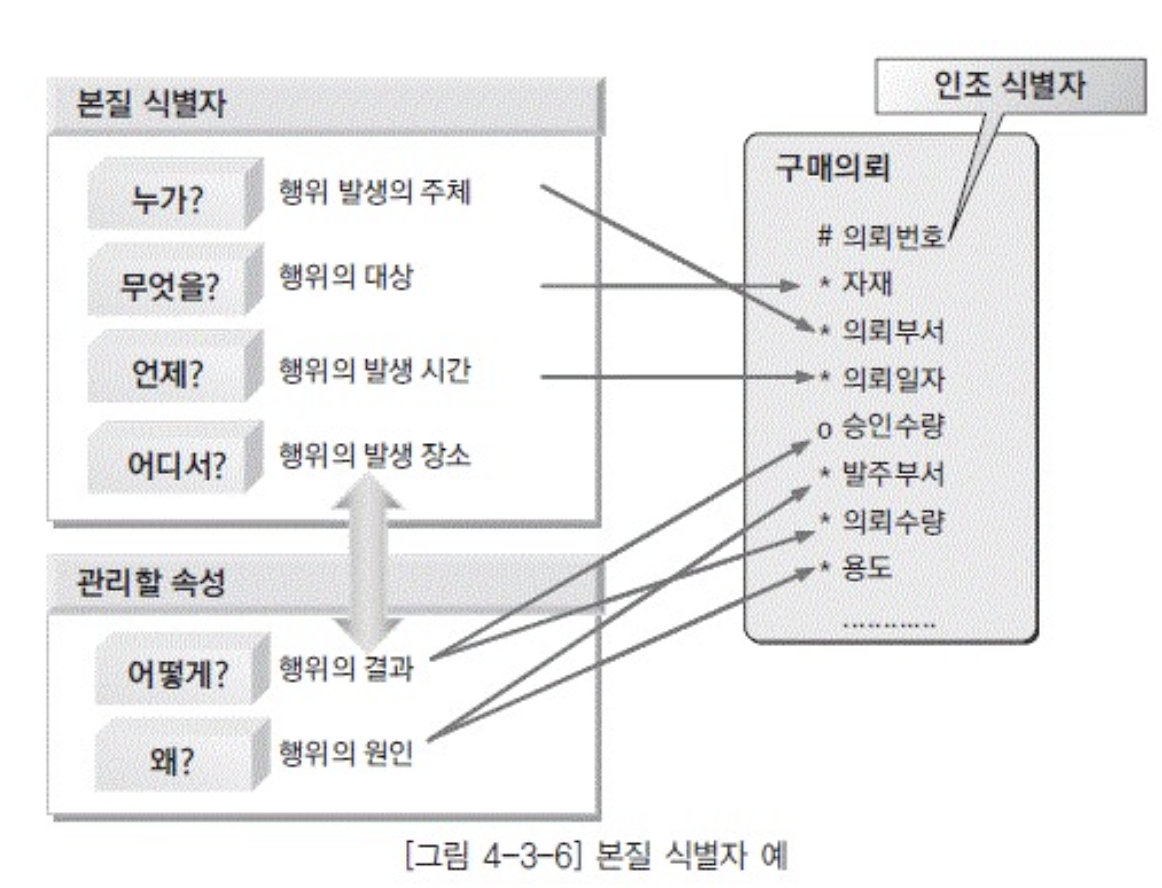
- 키엔티티의 본질 식별자
- 혼자서도 정의될수 있는 엔티티 == 키엔티티
- 사원번호(근데 사원번호보단 주민번호가 더 본질 식별자에 가깝지만 보안문제 잇음)
- 행위 엔티티의 본질 식별자
- 절대 종속 상대종속 의미
- 나를 태어나는데 절대적인 영향을 주었는지
- 직접종속, 간접종속 의미
- 1촌이냐 1촌이상이냐
- 여기선 본질식별자가 절대 종속이면서 직접종속이여야함
- 6하원칙을 이용해서 본질 식별자를 찾을 수 있음(why how는 관리할 속성)
- 절대 종속 상대종속 의미
- 키엔티티의 본질 식별자
- 후보 식별자 도출
- 본질 식별자를 기본으로 유일성 유지목적과 참조해야하는 목적을 판단하여 최종식별자를 확정해야함
- 식별자 중 최종시결자가 아닌것이며 아래조건을 만족함
- 조건
- 유일성
- 나머지 속성을 직접 식별
- not null
- 집합으로 후보식별자를 선택하는 경우 개념적으로 유일
- 유일하다고 확신해야함(이름같은건ㄴ 당장 유일하더라도 개념적으론 유일하지 않음)
- 자주 변경되지 않는것이어야함
- 대체(보조) 식별자
- 식별자로서의 역할을 충분히하는경우
- 가끔 대체 식별자로 연결맺는것이 유리한경우 의미가 있음
- 인조 식별자 지정
- 식별자 확정시 기존 본질 식별자를 그대로 인정 못하는 상황이 발생했을때 인조 식별자 지정
- ex ) 주민번호 를 사원번호(인조 번호)로
- 기준
- 최대한 범용적인 값 사용
- 유일한 값을 만들기 위한 인조식별자를 사용
- 하나의 인조식별자 속성으로 대체할 수 없는 형태를 주의함
- 어느 본질 식별자를 대체하는지 명확히해야함
- 편의성 단순성확보를 위해 사용할 수 있음
- 의미 체계화를 위해 사용할 수도 있음
- 내부적으로만 사용하는 경우도 사용할 수 있음
- 식별자 확정시 기존 본질 식별자를 그대로 인정 못하는 상황이 발생했을때 인조 식별자 지정
- 식별자 확정
- 주변 엔티티 상황을 종합적으로 살피고 수렴해야한다
- uid bar 두가지 의미(참조,상속과 관련됨) - 까마귀 발의 수직직선을말함
- 식별자로서의 역할
- 정보로서의역할
- 절차
- 키엔티티 식별자 확정
- 메인엔티티 식별자 확정
- 주변사오항공유하고 인조식별자를 생성하기도함용
- 하위 엔티티 식별자 확정
- 인조 속성 안사용하는게 바람직함
정규화
보통3차까지 사용
- 정규화 안할시 생길 수 있는 이상(문제)
- 변경(갱신), 삽입(입력),수정,삭제이상 등이있음
- 무결성이 파괴됨
- 장점
- 중복값줄어듬
- null값줄어듬
- 복잡한 코드로 데이터 모델 보완 필요없음
- 새로운 요구사항 발견도움
- 데이터구조를 안정을 최대화함
- 업무규칙의 정밀한 포착을 보증함
- 정규화 단계
- https://mangkyu.tistory.com/110
- 1차: 도메인이 우너자값
- 2차 : 부분적 종속제거
- 3차 이행적 종속제거
- BCNF : 결정자이면서 후보키아닌거 제거
- 모든 결정자가 키어야함
- 변경 이상 현상 이 생길 수 있음
- 4차 : 다치종속 제거
- 5차 : 조인종속성 이용
M:M 관계 해소
- 문제
- 데이터 종속성 결정어렵게함
- 논리적 완성과 부분집합 식별의 문제를 제한함
- 릴레이션 엔티티를 추가하여 M:1로 바까야함
참조 무결성 규칙 종류
- 입력규칙
- 자식 인스턴스를 입력할때
- depentent : 대응되는 부모 실체 인스턴특가 있는 경우에만 자식실체에 입력가능
- automatic : 자식 실체 입력 항상 허용 , 대응되는 부모 없을때 자동생성
- nullifty : 자식 실체 입력 항상 허용 , 대응 부모 없을시 자식 실체의 FK를 null처리
- default : 자식 실체 입력 항상 허용 , 대응 부모 없을시 참조키를 지정된 기본값으로 처리
- customized: 특정조건시에만 입력허용
- no effect: 조건없이 자식 입력허용
- 삭제 규칙
- 부모 인스턴스를 삭제할때 or 주식별자를 수정할때
- retrict : 대응되는 자식이없으면 허용
- cascade : 부모 삭제 항상허용, 대응되는 자식은 자동삭제
- nullify : 부모 삭제 항상허용, 대응 되는 자식fk를 Null
- default : 부모 삭제 항상허용, 대응 자식 fk를 기본값
- customized
- no effect
이력관리 정의
논리 데이터 모델링에서 물리 데이터 모델링 단계로 넘어오면서 고려해야 하는 작업의 사례는 다음과 같다.
Super/Sub관계의 엔터티를 몇 개의 테이블로 만들 것인가
배타적 관계 엔터티의 외부키 를 몇 개로 할 것인가 (Arc) (Foreign Key)
성능 향상을 위해 테이블을 추가해야 할 것인가 혹은 통합해야 할 것인가
통계 작업을 위해 합계(Summary) 테이블 같은 임시성 테이블을 몇 개로 할 것이며 유일키를 무엇으로 할 것인가
테이블의 칼럼을 다른 테이블에 중복할 것인가 중복한다면 어떤 애플리케이션이 관련되어 있는 가, 인덱스의 설정 스냅샷 (Snapshot) 또는 뷰(View) 등의 객체가 필요한가
분산 환경에서 테이블을 중복할 것인가 중앙에 필요한 테이블을 따로 가져갈 것인가
데이터가 분산 환경에서 이동 시 문제를 어떻게 해결할 것인가
물리데이터 모델링
dbma출현으로 많은부분이 dbma에서처리되고잇음
여기서 테이블로 확정
RDM이라고도함
성능도 고려
논리 - 물리모델 변환
서브타입 변환
- 예시 : 추후 예시 모델
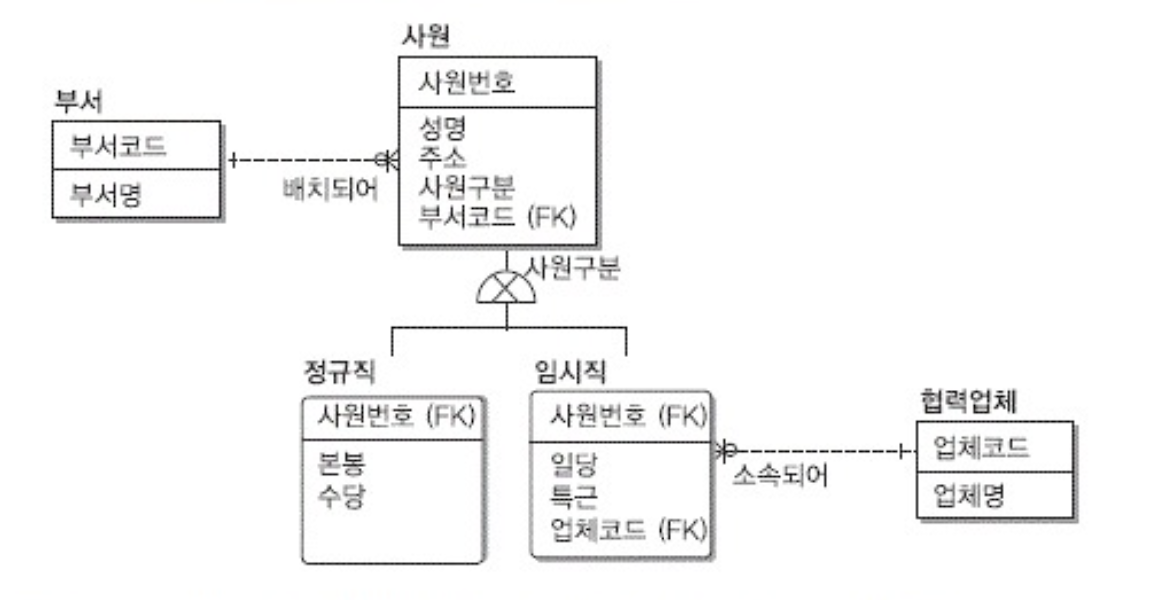
- 슈퍼타입 기준 테이블 변환> 하나로 만듬
- 서브타입을 슈퍼타입에 포함하여 하나의 테이블로 만듬
- 주로 서브타입에 정보가 적을때 사용
- 모든 서브타입의 데이터를 포함해야함
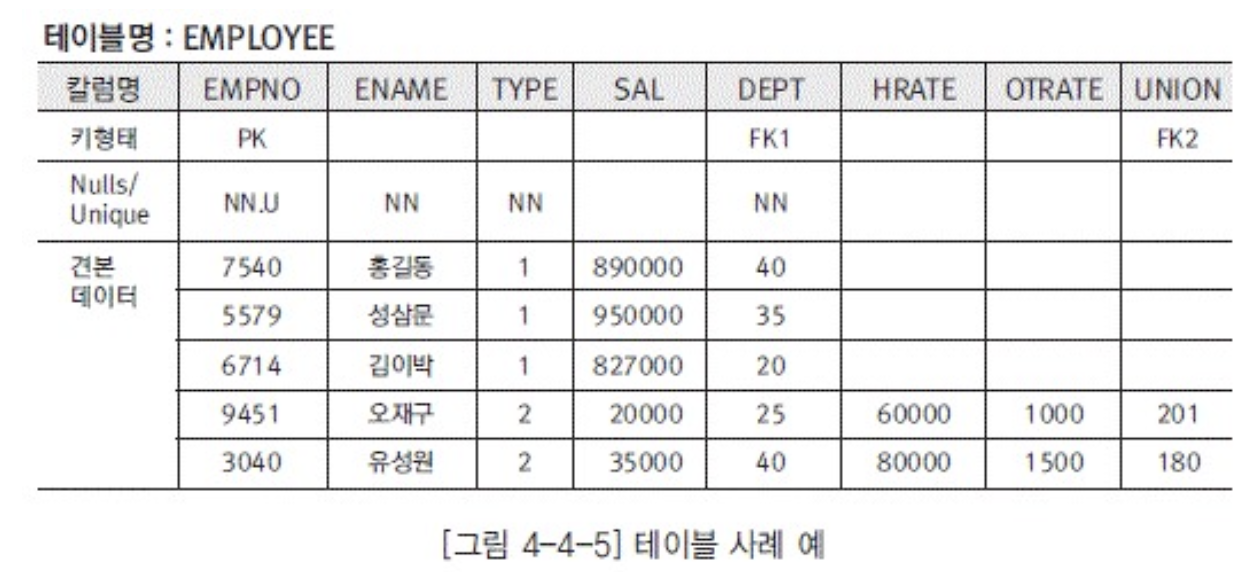
- 절차
- 슈퍼타입으로 테이블 명칭 부여
- 서브타입을 구분할 수 있도록 칼럼 추가
- 슈퍼타입의 속성과 서브타입의 속성을 칼럼명으로
- 슈퍼타입의 관계와 서브타입의 관계를 FK
- 이렇게 하나의 테이블로 통합하면 유리한경우
- 데이터엑세스가 좀 김편
- 뷰를 활용하여 서브타입만 엑세스하거나수정가능
- 조인 감소효과가 있어 적은 sql로 처리
- 하나로하는게 불리한경우
- 서브타입의 notnull제한 불가
- 가로든세로든 크기가 겁나게 증가할 수 도있음
- 처리시마다 구분이 필요한경우 별로임
- 서브타입 기준 테이블 변환
- 각서브타입에 슈퍼타입속성들을 추가해서 각 서브타입을 하나의 테이블로 만듬
- 서브타입이 많은 정보를 들고잇을때 사용
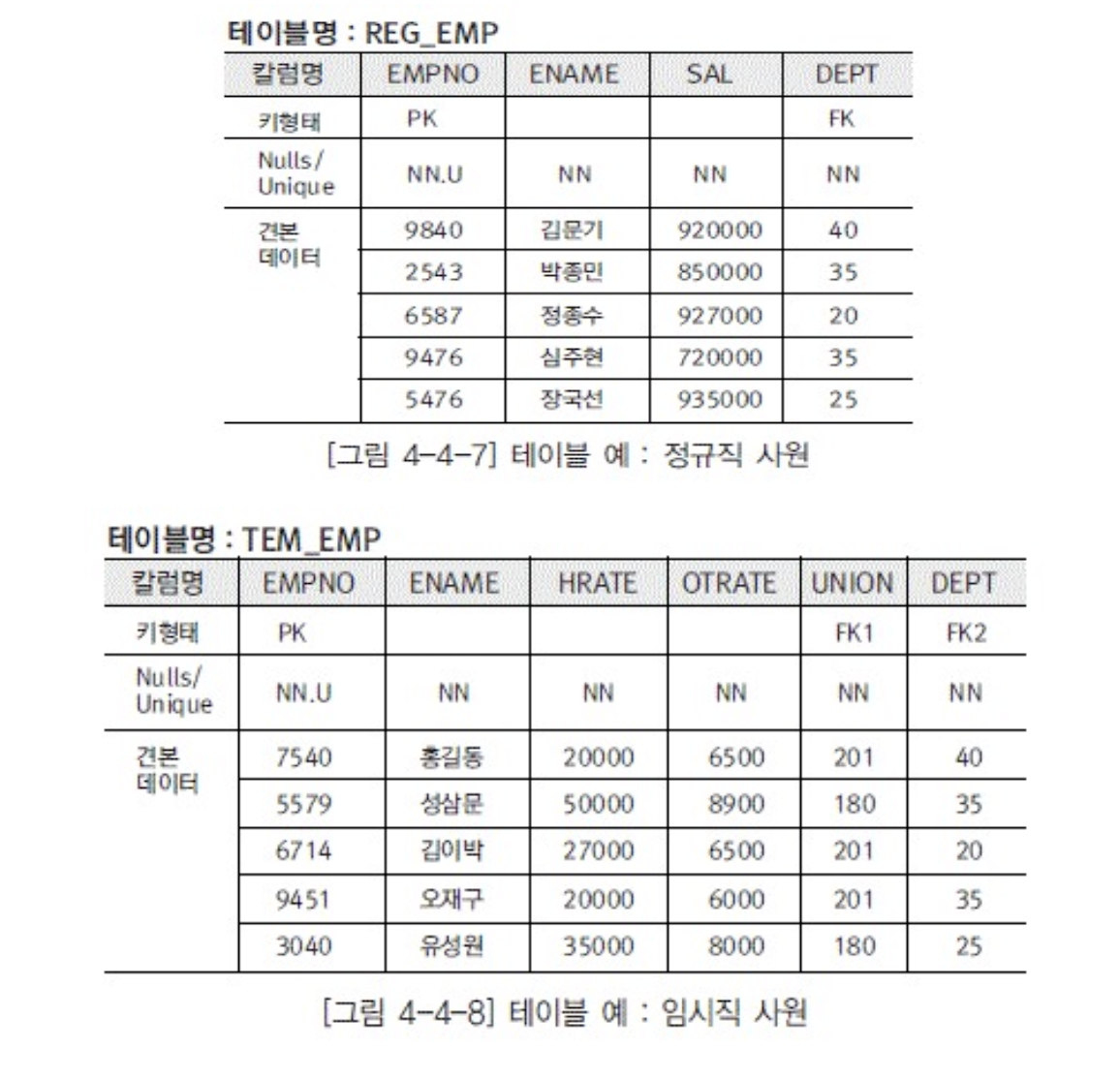
- 절차
- 서브타입마다 테이블 명칭부여
- 서브타입속성을 칼럼명으로
- 테이블마다 슈퍼타입의 속성을 칼럼으로(연관되는것만)
- 서브타입마다 해당되는 관계를 FK
- 이렇게 하는게 유리한경우
- 단위 테이블 크기 감소
- 각 서브타입 유형구분이 불필요함
- 전체스캔시 유리
- 불리
- 서브타입구분없이 처리하는경우 유니온 발생
- 처리속도감소할확률 증가
- 트랙젝션처리시 빡셈
- sql 통합어려움
- 여러테이블 합친 뷰 조회만 가능
- uid관리빡셈
- 개별타입 기준 테이블 변환
- 슈퍼타입, 서브타입 각각을 다 테이블로 변환
- 슈퍼타입-서브타입 = 1:1
- 전체데이터 처리가 빈번하게 발생할 경우, 칼럼수가 너무많아질 경우, 처리범위가 넒을경우 사용
- 케이스
- 서브타입을 테이블로 분리
- 속성 값이 같으면 서로변환된것으로 간주
- 서브타입을 통합테이블로 생성
- 서브타입을 테이블로 분리
속성-칼럼 변환
- 표준화된 약어사용
- NN : notnull, U : unique
- primary uid는 pk로 변환됨
- | ( uid bar) 가 있으면 해당 fk에 pk라고 표시해야함
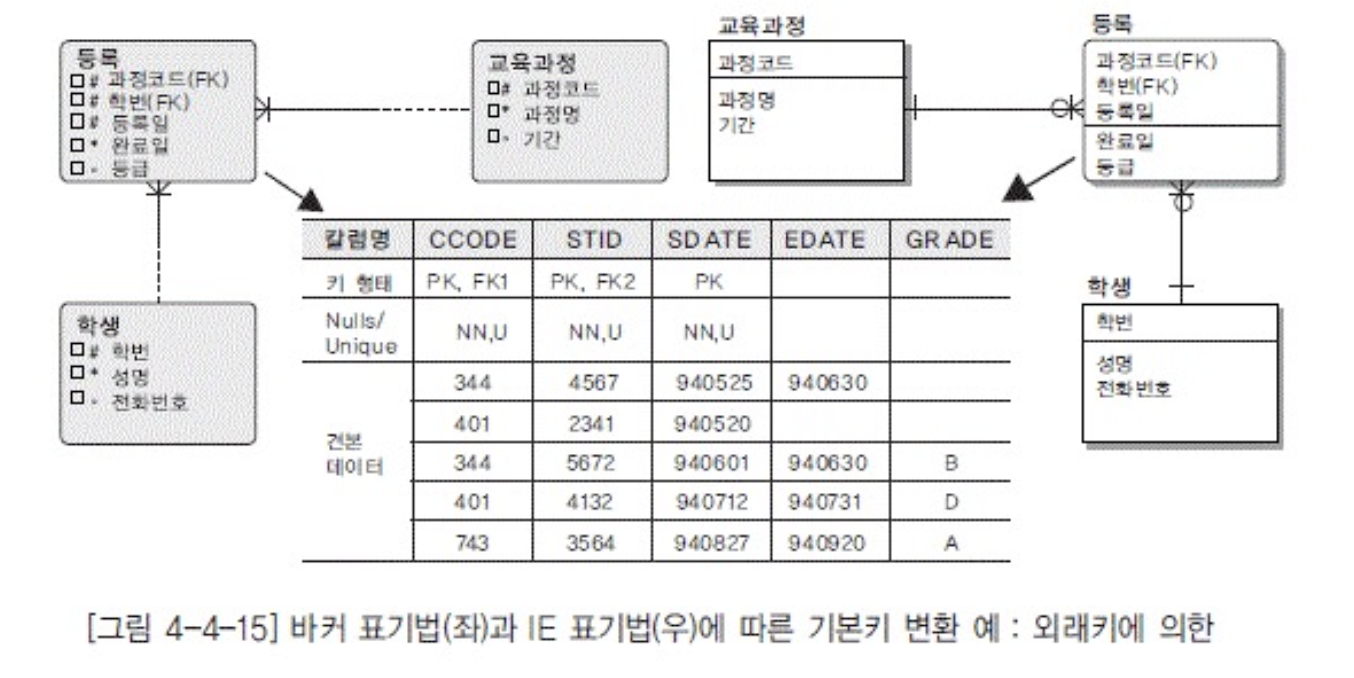
- secondary(대체) uid
- 이거 U 해야함
관계 변환
optional 일때에 따라서 FK에 NN여부가 갈림
최대한 NN이되게 (FK)가..ㅇㅇ;
1:1
- 무조건 상대 테이블 가져야하는 경우 인 테이블에서 상대를 FK로 두면됨 NN으로
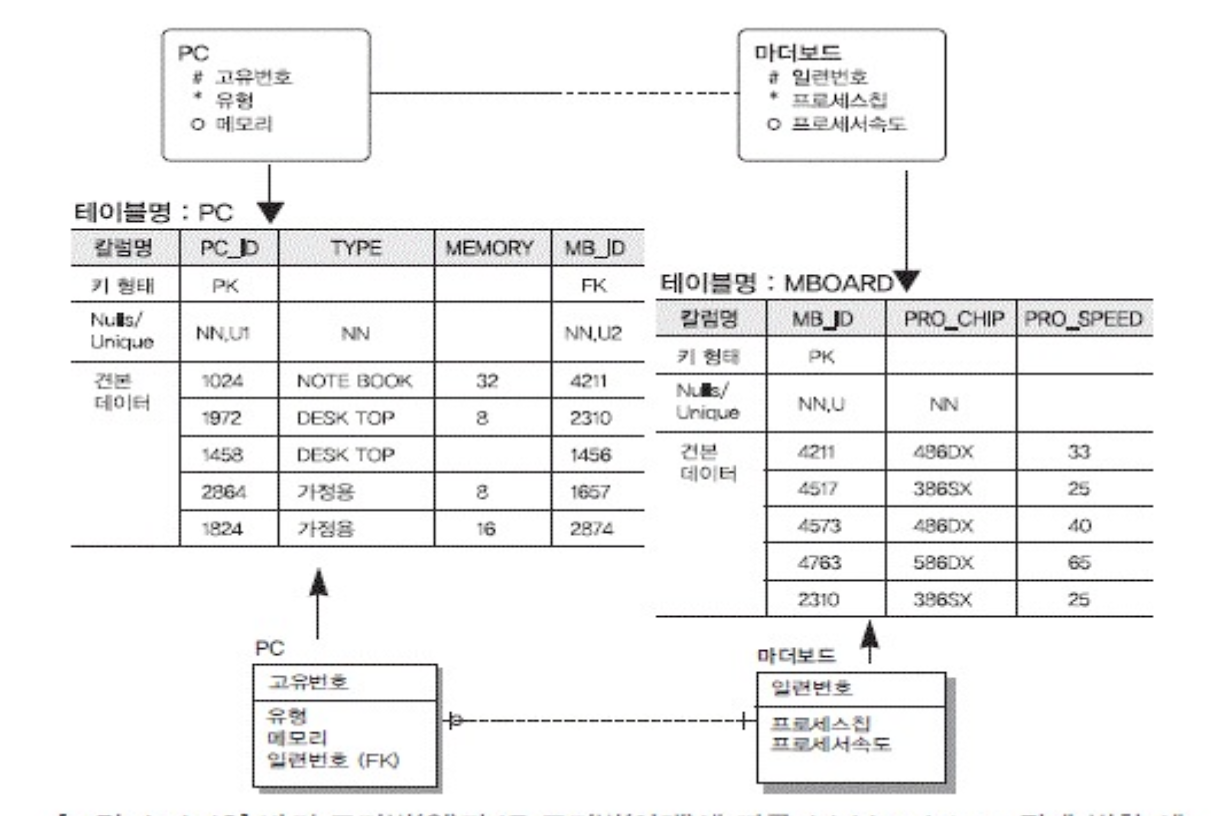
- 둘다 옵셔널이면 많이쓰는 애가 외래키를 가지면 됨
- 무조건 상대 테이블 가져야하는 경우 인 테이블에서 상대를 FK로 두면됨 NN으로
1:M 순환관계 변환
- 이건 옵셔널이아닐수없음 무한루프됨^^
- NN이 될 수 없음(FK가 ㅇㅇ)
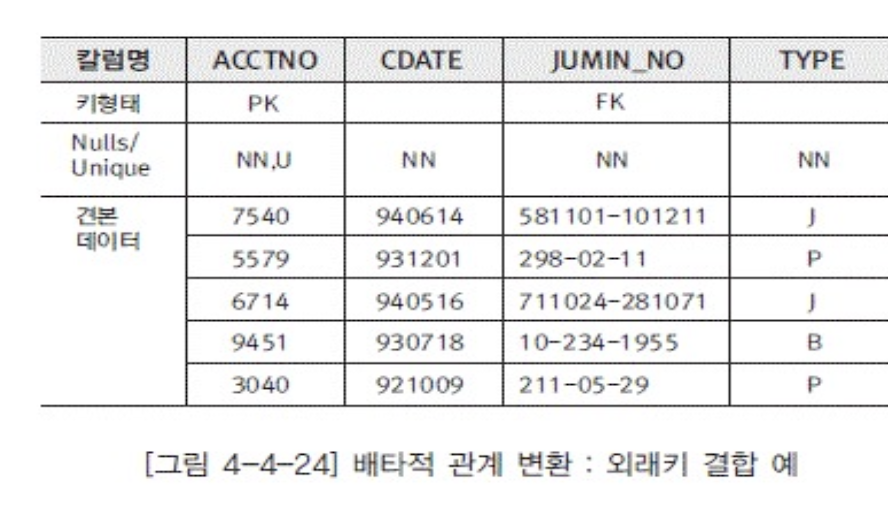
베타적 관계변환(약간 enum느뀜?)
- 외래키 분리방법
- 각각의 관계를 칼럼으로 생성함
- 각 키가 옵셔널이어야하고 제약조건 추가로 생성해줘야함
- 외래키 결합방법
- 타입이라는 칼람을 추가해서
- 보면 JUMIN_NO는 번호다 타입으로본다음에 번호로 식별가능
- 외래키 분리방법
관리상 필요한 칼럼 추가
말그대로관리상 필요한 칼럼을 추가 like 생성일지
데이터 타입 선택
dbms 특성과 성능 고려해야함
- char : 보통 4000,8000이 리미티드 , long text의 대안 잇음, 고정길이여부에따라도 달라짐
- numberic
- boolean
- integer
- decimal(소수)
- money
- date
- 정밀하냐 정밀안하냐에 따라 나뉨(안정밀한 건 small)
데이터 표준 적용
- 전사적으로 미리 생성한 데이터 표준을 따라야함
- like 표준용어 표준도메인 표준 명명 규칙 등
- 대상
- db, 스토리지그룹, table, column,index,view
반정규화
테이블 분할
- 수직,수평으로 분할
- 파티셔닝이라고도함
- 수평 분할
- 개체 개수가 졸라게 많을때씀
- dbms차원에서 제공하고잇음
- 수직 분할
- 특별히 자주조회되는 칼람이 잇거나
- 칼럼크기가 너무크거나
- 특정칼람에 보안을 해야하거나
- 테ㅐ이블 내 칼럼에 권한 제어기능을 제공하진 않음
- 보안을 적용하고자 별도의 테이블로 만들어서 권한 제어를함
- 조회위주 갱신위주 등 접근법이다를경우
- 갱신할때 락적용해야 무결성지킬수 잇음
- dbms 버전 별로 검토해야함
중복 테이블 생성
집계함수같은건 여러 테이블에서 데이터를 추출함
연산이많음 > 통계테이블같이 중복테이블을 추가할 수 있음
일관성 보장 유의해야함.
- 판단 근거
- 정규화에 충실하면 종속성활용성은 굿인데 수행속도가 구려짐
- 많은범위를 자추처리해야함
- 특정범위의 데이터만 자주처리해야함
- 처리범위를 줄이지않고는 수행속도를 개선할수 읎음
- 인덱스 조정이나 부분범위처리로 유도, 클러스터링으로 해결할 수 있는지 검토
- 유형
- 집계테이블
- 데이터베이스 트리거의 오버해드에 주의하고 일관성보장에 유의하여야함
- 클러스터링, 결합인덱스,고단위 sql로 해결한 경우 있음요 검토해야함
- 지나친 집계테이블 ㄴㄴ 활용도를 분석해야함
- 진행테이블
- M:M관계가 포함된 처리과정을 추적 관리하는경우
- 활용도 조아지도록 기본키선정
- 필요에 따라 적절한 칼람추가해서 집계테이블 역할도하는 다목적테이블구상
- 다중테이블클러스터링이나 조인 sql을 이용하여 해결가능한지 검토
- 집계테이블
중복 칼럼 생성
- 빈번하게 조인
- 속도가 중요(온라인 실시간)
- 엑세스 조건으로 자주사용
- 조건을 모아서 변별성을 늘릴 수 있음
- 접근경로 단축
- 미리 연산하여 중복칼럼생성가늠
- 여러개 로우로 구성된느 값을 하나로 나열하는 경우
- 인위적인 기본키를 추가하는경우(기본키가너무길거나 여러개일때)
- 유의사항
- 다중테이블클러스터링 혹은 sql group처리해도문제없는지 검토
- 상대 테이블의 rowid(데이터 주소)를 복사하는경우가 효과적일때도잇음
- 일관성유지
- 지나치면 데이터처리 오버해드생김
- 엑세스 경로 최적화 방안을 보다 강구해야함
- 원본칼럼만 수정해야함